Data Intensive Applications
My notes on Chapter 1 of Designing Data-Intensive Applications, by Martin Kleppmann. I was familiar with a few of the concepts before reading, but it was a great refresher and I learned many new things. Basic Software Engineering knowledge is assumed.
Thinking about Data Systems
Our applications use and operate on data for a variety of reasons, some of the most common ones being:
- Storage and Retrieval: Databases, e.g. Postgres
- Caching: Storing the result of an expensive operation to speed up reads, e.g. Redis
- Search Indexes: Allowing users to query and filter large datasets, e.g., Google Search
It's common to lump databases, queues, caches etc. into the umbrella term, data systems. As new tools emerge, the boundaries have become blurred, for example, Apache Kafka is a message queue that guarantees database level durability.
Whilst knowledge of data systems is crucial, it's more important to understand how to interface with them rather than implement them. Instead of building a storage engine from scratch, most programmers work on Application Code or Business logic, this is the part that "glues" several data systems and APIs together to serve customers or meet a business goal.
Take an application like a todo list for example.
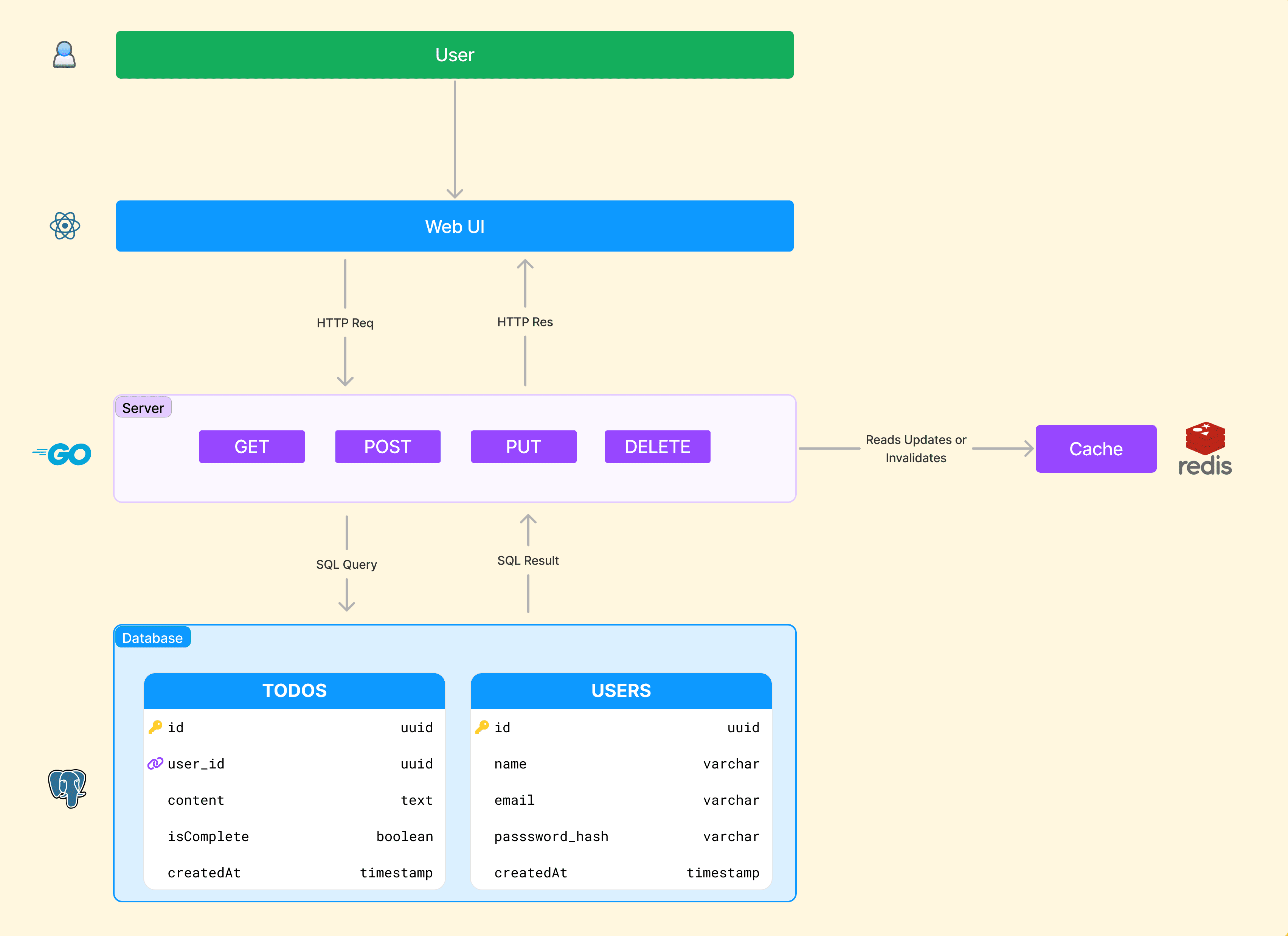
Notice our application code, denoted by the server section, interfaces with Postgres and Redis, two different data systems. If users had a lot of long detailed todos, we could even connect to a 3rd data system optimized for full text search, companies like Algolia make this quite simple.
When choosing what data systems to use and how to use them, Software Engineers care about functional requirements (the functionality that makes the app useful to users). Our todo app's functional requirements would be:
- Reading, creating, editing, or deleting a todo
- Signing in and out
If you're familiar with basic SQL, that's all accomplished, we have endpoints and Postgres tables that correlate to each requirement. However, there are implicit requirements that every software system shares. These are Reliability, Scalability and Maintainability.
Reliability
The ability of a system to function correctly and consistently over time, even in the presence of fault, this is also referred to as fault tolerance. Faults primarily manifest in 3 forms: Software errors, Hardware faults and Human errors often with overlap since humans, namely programmers, tend to cause software error.
Faults vs Failures vs Errors
Errors may lead to faults, and faults may lead to failures. Though many people use the terms interchangeably, especially fault and error, there are specific differences. If there's a faulty part of your code, the application can work fine if that part of the code doesn't run. However, if the code does run, you get an error. Fails to handle that error, it becomes a fault, which may cause the application to fail. Failure is typically non recoverable and the application must restart.
Software Errors
Software errors manifest most commonly in these forms:
- Bugs: A software bug that causes application crashes when given specific input. For example, the leap second bug on June 30, 2012, caused many Linux systems to hang due to a kernel bug.
- Resource Leaks: A runaway process that consumes all available memory, CPU, or disk space, causing the system to become unresponsive.
- Cascading Failures: A small failure in one component triggering a series of failures in dependent components, such as a network switch failure causing database disconnections and subsequent application errors.
If you're familiar with Go, you'd know that it's crucial to handle a returned error.
func main() {
db, err := sql.Open("postgres", "user=username dbname=mydb sslmode=disable")
/*
if you don't check that the error is null and gracefully handle it,
further interactions with the database will crash the app
*/
if err != nil {
log.Fatal(err)
}
defer db.Close()
}Similarly, in Javascript, you should wrap code that can error in a try catch.
async function fetchData() {
try {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
/* handle error */
}
const data = await response.json();
//...
} catch (error) {
console.error("Fetch error:", error);
//handle error
}
}Hardware Faults
As an application developer, these are a bit more out of your control. Fortunately, one of the big selling points of Cloud Providers like AWS is that they abstract away the hardware for your. Cloud platforms are designed to prioritize flexibility and elasticity over single machine reliability, however, this does not mean they can’t occasionally occur.
Common Hardware Faults include:
- Disk Failures: Hard disks have a mean time to failure (MTTF) of about 10 to 50 years, in large storage clusters, you might expect one disk to fail per day.
- Power Failures: Power outages or fluctuations can cause system crashes and data corruption. Redundant power supplies and backup generators are common mitigations.
- Network Failures: Unplugging the wrong network cable or router malfunctions can lead to network partitions, affecting the availability and consistency of distributed systems.
Human Errors
Human errors are generally the most common cause of system failures. This is because humans interact with systems in complex ways and can make mistakes that automated systems might not predict or prevent. Studies have shown that configuration errors and operational mistakes by humans are leading causes of outages in large-scale systems.
Common Examples include:
- Configuration Errors: Misconfiguring a system setting, such as a url connection string, can lead to service outages.
- Deployment Errors: Accidentally deploying untested or buggy code to production can cause system failures.
- Operational Mistakes: Actions like accidentally deleting critical data or failing to monitor system health can lead to major incidents.
Some ways to mitigate human errors are, unit testing, integration testing, fully featured non production environments (eg: staging) and monitoring and logging (aka telemetry).
Scalability
Scalability is concerned with how our our software handles load. The todo architecture from before would work for 100s to low 10,000s of concurrent users, however, as it grows to 100,000s we’d likely begin to put too much load on a single CPU. Imagine 1M people tried to add a todo at the same time. If one machine had to handle that, it’d likely crash and then all of those users would lose data.
To understand and plan for scalability, we describe the current load using load parameters. These could be requests per second, read/write ratios, active users, cache hit rates, etc. A great example of an application that faced scaling issue is Twitter. Twitter handles operations like posting tweets and displaying home timelines, which have different load characteristics.
TLDR on how Twitter handles Scale
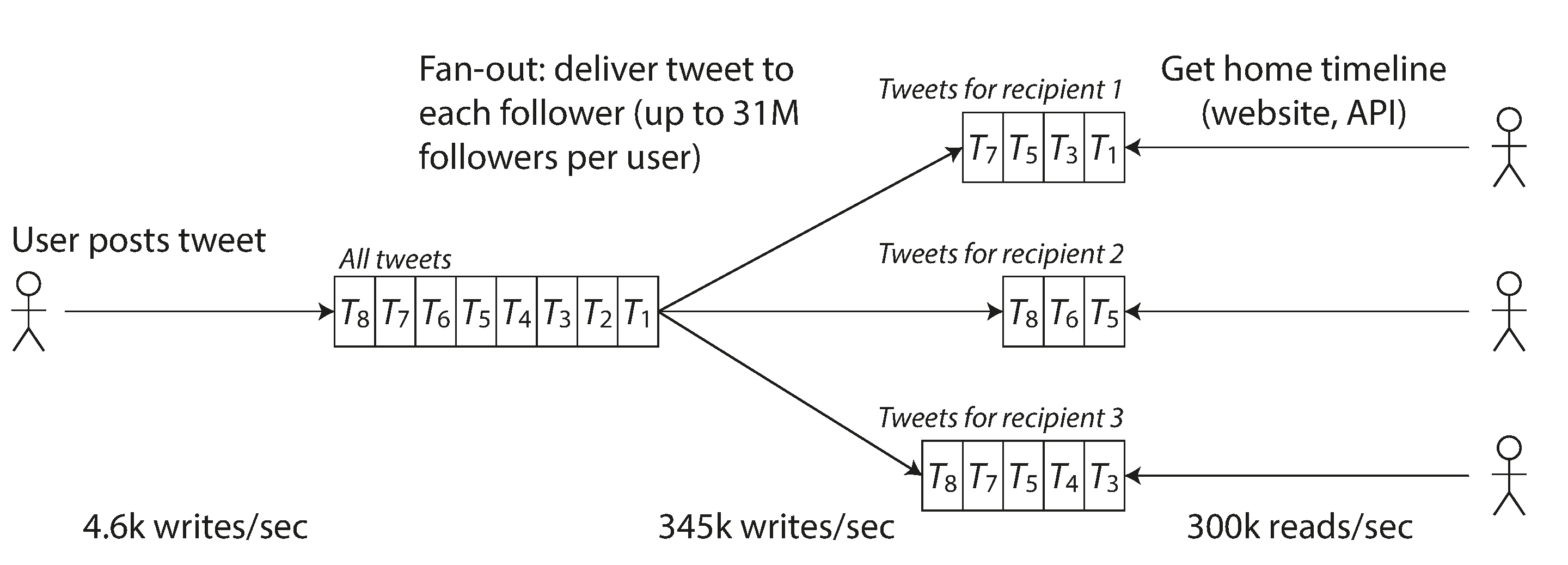
It’s like a mailbox. Twitter used a technique called fan-out. The intuition behind this is that people tend to tweet far less than they just open the app. Thus, it makes sense to send tweets to each follower at the time of posting instead of to querying the entire database whenever someone opens the app. Note that there are edge cases for celebrities with >1M followers where the logic must change since sending the tweet to so many people at once would make the experience bad for the tweeter.
Post Tweet Operation
- Average Load: 4.6k requests/second, peaking at 12k requests/second
- Description: A user posts a tweet, which needs to be delivered to all their followers
View Timeline Operation
- Average Load: 300k requests/second
- Description: Users view tweets posted by people they follow, requiring access to a personalized home timeline
Initially, when a user requests their home timeline, the system looks up all the people they follow, retrieves all the tweets from those users, and merges them in real-time. This method was inefficient under heavy load, as merging tweets on-the-fly required significant computational resources, causing performance issues.
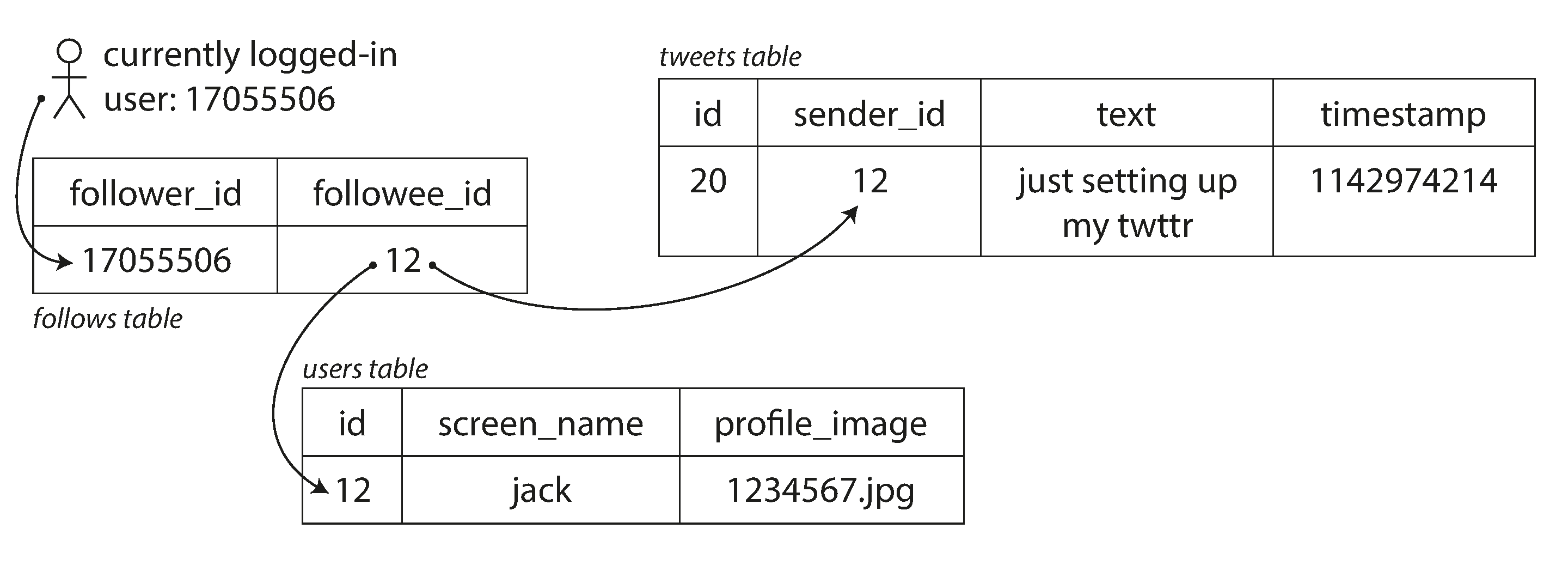
To Optimize, Tweets are now "fanned out" to each follower’s home timeline cache at the time of posting. This means each new tweet is immediately inserted into the home timeline cache of every follower. Reading the home timeline becomes faster since the tweets are pre-computed and stored in the follower’s cache.
Describing Performance
When describing the load on your system, you need to investigate what happens when the load increases. This can be approached in two ways:
- Fixed Resources, Increasing Load: How is system performance affected when load parameters increase while system resources (CPU, memory, network bandwidth) remain unchanged?
- Increasing Resources, Fixed Performance: How much do you need to increase resources to maintain performance when load parameters increase?
These questions require performance metrics to be properly answered. The performance of a system can be described using different metrics, depending on the system type:
Batch Processing Systems
- Throughput: Number of records processed per second or total time to run a job on a dataset of a certain size.
Online Systems
- Response Time: Time between a client sending a request and receiving a response.
Latency and Response Time
- Latency: The time a request is waiting to be handled.
- Response Time: Includes actual processing time plus network and queuing delays.
Response time varies due to several factors, including network delays, server processing variations, and other random events. It’s better to consider response time as a distribution of values rather than a single number.
Response Time Distribution
Response times should be evaluated using percentiles:
- Median (p50): The midpoint of the response times.
- 95th Percentile (p95): 95% of requests are faster than this value.
- 99th Percentile (p99): 99% of requests are faster than this value.
High percentiles (tail latencies) are critical for user experience as they represent the slowest responses, which can significantly impact perceived performance. We don’t usually use the average response time since outliers can largely affect this.
High percentiles are crucial in backend services because an end-user request often requires multiple backend calls. If any one of these backend calls is slow, the entire end-user request will be slow. This is known as tail latency amplification.
Approaches for Coping with Load
- Vertical Scaling (Scaling Up): Moving to a more powerful machine or upgrading a part of the machine like the CPU.
- Horizontal Scaling (Scaling Out): Distributing the load across multiple machines, also known as a shared-nothing architecture.
Good architectures usually combine both approaches. Systems that can automatically add computing resources in response to load increases are described as elastic.
Maintainability
Maintainability is crucial since most software costs arise not from initial development but from ongoing maintenance tasks such as fixing bugs, keeping systems operational, adapting to new platforms, and adding features. Maintenance is often disliked due to the challenges of dealing with legacy systems and outdated platforms.
To minimize maintenance pain, three key design principles should be considered:
- Operability: This involves making it easy for operations teams to keep the system running smoothly. Good operability includes:
- Effective monitoring and quick restoration of services.
- Efficiently tracking and resolving system issues.
- Keeping software updated and ensuring security.
- Establishing good deployment and configuration practices.
- Maintaining system knowledge within the organization.
- Simplicity: Reducing complexity makes systems easier to understand and maintain. Complexity can lead to higher maintenance costs and increased risk of bugs. Achieving simplicity involves:
- Removing unnecessary complexity (accidental complexity).
- Using abstractions to hide implementation details and facilitate reuse.
- Ensuring that the system is easy to understand and reason about.
- Evolvability: Systems should be designed to adapt easily to changing requirements. This includes:
- Using Agile practices for small-scale changes and applying similar principles at a larger system level.
- Refactoring systems to accommodate new requirements or improved architectures.
- Keeping the system simple and modular to facilitate easy modifications.
By focusing on operability, simplicity, and evolvability, software systems can be designed to be more maintainable, reducing long-term costs and improving overall reliability and performance.